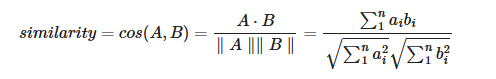RAG的基本原理 大语言模型(LLM)在生成内容时,虽然具备强大的语言理解和生成能力,但也面临着一些挑战。例如,LLM有时会生成不准确或误导性的内容,这被称为大模型“幻觉”。此外,模型所依赖的训练数据可能过时,尤其在面对最新的信息时,生成结果的准确性和时效性难以保证。对于特定领域的专业知识,LLM 的处理效率也较低,无法深入理解复杂的领域知识。因此,如何提升大模型的生成质量和效率,成为了当前研究的重要方向。
在这样的背景下, 检索增强生成(Retrieval-Augmented Generation,RAG) 技术应运而生,成为AI领域中的一大创新趋势。从本质上讲,RAG(Retrieval-Augmented Generation)是一种旨在解决大语言模型(LLM)“知其然不知其所以然”问题的技术范式。它的核心是将模型内部学到的“参数化知识 ”(模型权重中固化的、模糊的“记忆”),与来自外部知识库的“非参数化知识 ”(精准、可随时更新的外部数据)相结合。其运作逻辑就是在 LLM 生成文本前,先通过检索机制从外部知识库中动态获取相关信息,并将这些“参考资料”融入生成过程,从而提升输出的准确性和时效性 。
那么,RAG 系统是如何实现“参数化知识”与“非参数化知识”的结合呢?如图 1-1 所示,其架构主要通过两个阶段来完成这一过程:
检索阶段:寻找“非参数化知识”
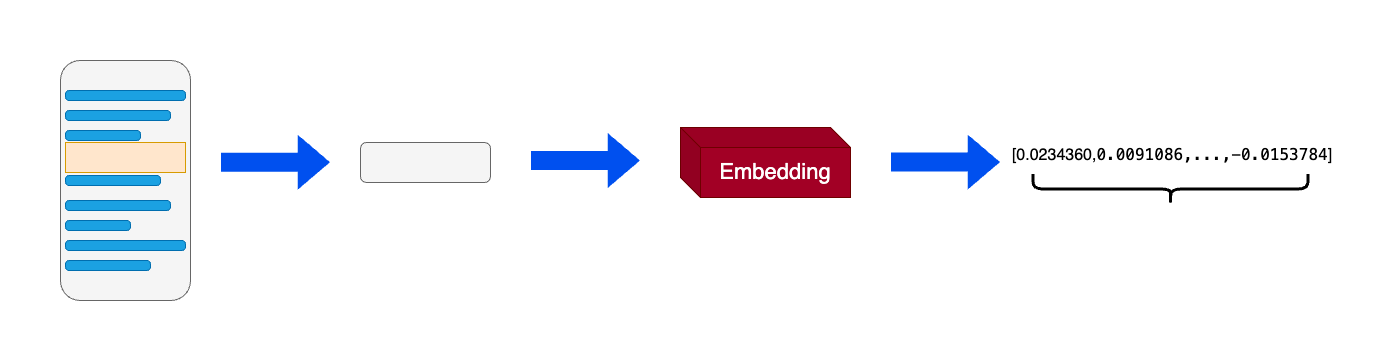
知识向量化 :嵌入模型(Embedding Model) 充当了“连接器”的角色。它将外部知识库编码为向量索引(Index),存入向量数据库 。语义召回 :当用户发起查询时,检索模块利用同样的嵌入模型将问题向量化,并通过相似度搜索(Similarity Search) ,从海量数据中精准锁定与问题最相关的文档片段。
生成阶段:融合两种知识
上下文整合 :生成模块 接收检索阶段送来的相关文档片段以及用户的原始问题。指令引导生成 :该模块会遵循预设的 Prompt 指令,将上下文与问题有效整合,并引导 LLM(如 DeepSeek)进行可控的、有理有据的文本生成。
搭建向量知识库 向量及向量知识库 在机器学习和自然语言处理(NLP)中,{ % span red,词向量(word embedding)%} 是一种以单词为单位将每个单词转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。{ % span red,词向量 %}背后的主要想理念是相似或相关的对象在向量空间中的距离应该很近。
例如,我们可以使用词向量来表示文本数据。在词向量中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。例如,”king” 和 “queen” 这两个单词在向量空间中的位置将会非常接近,因为它们的含义相似。而 “apple” 和 “orange” 也会很接近,因为它们都是水果。而 “king” 和 “apple” 这两个单词在向量空间中的距离就会比较远,因为它们的含义不同。
词向量实际上是将单词转化为固定的静态的向量,虽然可以在一定程度上捕捉并表达文本中的语义信息,但忽略了单词在不同语境中的意思会受到影响这一现实。因此在RAG应用中使用的向量技术一般为通用文本向量(Universal text embedding),该技术可以对一定范围内任意长度的文本进行向量化,与词向量不同的是向量化的单位不再是单词而是输入的文本,输出的向量会捕捉更多的语义信息。
在 RAG(Retrieval Augmented Generation,检索增强生成) 方面向量的优势主要有两点:
向量比文字更适合检索。当我们在数据库检索时,如果数据库存储的是文字,主要通过检索关键词(词法搜索)等方法找到相对匹配的数据,匹配的程度取决于数据库中的文档中是否含有查询句中的关键词;而向量中包含了原文本的语义信息,可以通过计算问题与数据库中数据的点积、余弦距离、欧几里得距离等指标,直接获取问题与数据在语义层面上的相似度; 向量比其它媒介的综合信息能力更强,当传统数据库存储文字、声音、图像、视频等多种媒介时,很难去将上述多种媒介构建起关联与跨模态的查询方法;但是向量却可以通过多种向量模型将多种数据映射成统一的向量形式。
在搭建RAG系统时,我们往往可以通过向量模型来构建向量,我们可以选择:
使用各个公司的 Embedding API 在本地使用向量模型将数据构建为向量
向量数据库 是用于高效计算和管理大量向量数据的解决方案。向量数据库 是一种专门用于存储和检索向量数据(embedding)的数据库系统。它与传统的基于关系模型的数据库不同,它主要关注的是向量数据的特性和相似性。
在向量数据库 中,数据被表示为向量形式,每个向量代表一个数据项。这些向量可以是数字、文本、图像或其他类型的数据。向量数据库使用高效的索引和查询算法来加速向量数据的存储和检索过程。
向量数据库 中的数据以向量作为基本单位,对向量进行存储、处理及检索。向量数据库通过计算与目标向量的余弦距离、点积等获取与目标向量的相似度。当处理大量甚至海量的向量数据时,向量数据库索引和查询算法的效率明显高于传统数据库。
Chroma :是一个轻量级向量数据库,拥有丰富的功能和简单的API,具有简单、易用、轻量的优点,但功能相对简单且不支持GPU加速,适合初学者使用。Weaviate :是一个开源向量数据库。除了支持相似度搜索和最大边际相关性(MMR,Maximal Marginal Relevance)搜索外还可以支持结合多种搜索算法(基于词法搜索、向量搜索)的混合搜索,从而提高搜索结果的相关性和准确性。Qdrant :Qdrant使用 Rust 语言开发,有极高的检索效率和RPS(Requests Per Second),支持本地运行、部署在本地服务器及Qdrant云三种部署模式。且可以通过为页面内容和元数据制定不同的键来复用数据。
数据处理 在RAG系统中,数据加载 是整个流水线的第一步,也是不可或缺的一步。文档加载器负责将各种格式的非结构化文档(如PDF、Word、Markdown、HTML等)转换为程序可以处理的结构化数据。数据加载的质量会直接影响后续的索引构建、检索效果和最终的生成质量。
文档加载器的主要功能:
文档格式解析 将不同格式的文档(如PDF、Word、Markdown等)解析为文本内容。元数据提取 在解析文档内容的同时,提取相关的元数据信息,如文档来源、页码等。统一数据格式 将解析后的内容转换为统一的数据格式,便于后续处理。
当前主流RAG文档加载器:
工具名称
特点
适用场景
性能表现
PyMuPDF4LLM PDF→Markdown转换,OCR+表格识别
科研文献、技术手册
开源免费,GPU加速
TextLoader 基础文本文件加载
纯文本处理
轻量高效
DirectoryLoader 批量目录文件处理
混合格式文档库
支持多格式扩展
Unstructured 多格式文档解析
PDF、Word、HTML等
统一接口,智能解析
FireCrawlLoader 网页内容抓取
在线文档、新闻
实时内容获取
LlamaParse 深度PDF结构解析
法律合同、学术论文
解析精度高,商业API
Docling 模块化企业级解析
企业合同、报告
IBM生态兼容
Marker PDF→Markdown,GPU加速
科研文献、书籍
专注PDF转换
MinerU 多模态集成解析
学术文献、财务报表
集成LayoutLMv3+YOLOv8
为构建我们的本地知识库,我们需要对以多种类型存储的本地文档进行处理,读取本地文档并通过前文描述的 Embedding 方法将本地文档的内容转化为词向量来构建向量数据库。在本节中,我们以一些实际示例入手,来讲解如何对本地文档进行处理。
我们选用 Datawhale 一些经典开源课程作为示例,具体包括:
对应PDF文档,我们可以使用 LangChain 的 PyMuPDFLoader 来读取知识库的 PDF 文件。 PyMuPDFLoader 是 PDF 解析器中速度最快的一种,结果会包含 PDF 及其页面的详细元数据,并且每页返回一个文档。
1 2 3 4 5 6 7 8 9 10 11 from langchain_community.document_loaders import PyMuPDFLoaderloader = PyMuPDFLoader("D:\Amadeus\Zeztz-demo1\datas\knowledge_db\pumpkin_book.pdf" ) pdf_pages = loader.load() print (f"载入后的变量类型为:{type (pdf_pages)} ," , f"该 PDF 一共包含 {len (pdf_pages)} 页" )—————————————————————————————————————————————————————————————————————————————————————————————————————— ouput:载入后的变量类型为:<class 'list' >, 该 PDF 一共包含 196 页
文档加载后储存在pdf_pages变量当中:
pdf_pages的变量类型为list,list当中的每一个元素为一个文档,该元素变量包含两个属性:
pdf_pages.meta_data为文档相关的描述性数据pdf_pages.page_content包含该文档的内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 print (f"每一个元素的类型:{type (pdf_page)} ." , f"该文档的描述性数据:{pdf_page.metadata} " , f"查看该文档的内容:\n{pdf_page.page_content} " , sep="\n------\n" ) ---------------------------------------------------------------------------------------------------------- 每一个元素的类型:<class 'langchain_core.documents.base.Document' >. ------ 该文档的描述性数据:{'producer' : 'xdvipdfmx (20200315)' , 'creator' : 'LaTeX with hyperref' , 'creationdate' : '2023-11-17T15:20:45+00:00' , 'source' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\pumpkin_book.pdf' , 'file_path' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\pumpkin_book.pdf' , 'total_pages' : 196 , 'format' : 'PDF 1.5' , 'title' : '' , 'author' : '' , 'subject' : '' , 'keywords' : '' , 'moddate' : '' , 'trapped' : '' , 'modDate' : '' , 'creationDate' : "D:20231117152045-00'00'" , 'page' : 1 } ------ 查看该文档的内容: 前言 “周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可 能多的读 者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些 想深究公式推 导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部 分公式补充 具体的推导细节。” 读到这里,大家可能会疑问为啥前面这段话加了引号,因为这只是我们最初的遐想,后来我们了 解到,周 老师之所以省去这些推导细节的真实原因是,他本尊认为“理工科数学基础扎实点的大二下学生应 该对西瓜书 中的推导细节无困难吧,要点在书里都有了,略去的细节应能脑补或做练习”。所以...... 本南 瓜书只能算是我 等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎 实点的大二 下学生”。 使用说明 • 南瓜书的所有内容都是以西瓜书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是 以西瓜书 为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书; • 对于初学机器学习的小白,西瓜书第1 章和第2 章的公式强烈不建议深究,简单过一下即可, 等你学得 有点飘的时候再回来啃都来得及; • 每个公式的解析和推导我们都力(zhi) 争(neng) 以本科数学基础的视角进行讲解,所以超纲的 数学知识 我们通常都会以附录和参考文献的形式给出,感兴趣的同学可以继续沿着我们给的资料进行深入 学习; • 若南瓜书里没有你想要查阅的公式,或者你发现南瓜书哪个地方有错误,请毫不犹豫地去我们GitHub 的 Issues(地址:https://github.com/datawhalechina/pumpkin-book/issues)进行反馈,在对应 版块 提交你希望补充的公式编号或者勘误信息,我们通常会在24 小时以内给您回复,超过24 小时未 回复的 话可以微信联系我们(微信号:at-Sm1les); 配套视频教程:https://www.bilibili.com/video/BV1Mh411e7VU 在线阅读地址:https://datawhalechina.github.io/pumpkin-book(仅供第1 版) 最新版PDF 获取地址:https://github.com/datawhalechina/pumpkin-book/releases 编委会 主编:Sm1les、archwalker、jbb0523 编委:juxiao、Majingmin、MrBigFan、shanry、Ye980226 封面设计:构思-Sm1les、创作-林王茂盛 致谢 特别感谢awyd234、feijuan、Ggmatch、Heitao5200、huaqing89、LongJH、LilRachel、LeoLRH、 Nono17、 spareribs、sunchaothu、StevenLzq 在最早期的时候对南瓜书所做的贡献。 扫描下方二维码,然后回复关键词“南瓜书”,即可加入“南瓜书读者交流群” 版权声明 本作品采用知识共享署名-非商业性使用-相同方式共享4.0 国际许可协议进行许可。
数据清洗 我们期望知识库的数据尽量是有序的、优质的、精简的,因此我们要删除低质量的、甚至影响理解的文本数据。\n,也在原本两个符号中间插入了\n,我们可以使用正则表达式匹配并删除掉\n。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 pdf_page.page_content = pdf_page.page_content.replace("\n" , "" ) ----------------------------------------------------------------------------------------------------------- 前言 “周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可 能多的读 者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那 些想深究公式推 导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析, 以及对部分公式补充 具体的推导细节。” 读到这里,大家可能会疑问为啥前面这段话加了引号,因为这 只是我们最初的遐想,后来我们了解到,周 老师之所以省去这些推导细节的真实原因是,他本尊认为“ 理工科数学基础扎实点的大二下学生应该对西瓜书 中的推导细节无困难吧,要点在书里都有了,略去的 细节应能脑补或做练习”。所以...... 本南瓜书只能算是我 等数学渣渣在自学的时候记下来的笔记,希 望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二 下学生”。 使用说明 • 南瓜书的所有 内容都是以西瓜书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是以西瓜书 为主线,遇到 自己推导不出来或者看不懂的公式时再来查阅南瓜书; • 对于初学机器学习的小白,西瓜书第1 章和第 2 章的公式强烈不建议深究,简单过一下即可,等你学得 有点飘的时候再回来啃都来得及; • 每个公 式的解析和推导我们都力(zhi) 争(neng) 以本科数学基础的视角进行讲解,所以超纲的数学知识 我们 通常都会以附录和参考文献的形式给出,感兴趣的同学可以继续沿着我们给的资料进行深入学习; • 若 南瓜书里没有你想要查阅的公式,或者你发现南瓜书哪个地方有错误,请毫不犹豫地去我们GitHub 的 I 可以微信联系我们(微信号:at-Sm1les); 配套视频教程:https://www.bilibili.com/video/BV1Mh411e7VU 在线阅读地址:https://datawhalechina.github.io/pumpkin-book(仅供第1 版) 最新版PDF 获取地址:https://github.com/datawhalechina/pumpkin-book/releases 编委会 主编:Sm1les、archwalker、jbb0523 编委:juxiao、Majingmin、MrBigFan、shanry、Ye980226 封面设计:构思-Sm1les、 创作-林王茂盛 致谢 特别感谢awyd234、feijuan、Ggmatch、Heitao5200、huaqing89、LongJH、LilRachel、LeoLRH、Nono17、 spareribs、sunchaothu、StevenLzq 在最早期的时候对南瓜书所做的贡献。 扫描下方二维码,然后回复关键词“南瓜书”,即可加入“南瓜书读者交流群” 版权声明 本作品采用知识 共享署名-非商业性使用-相同方式共享4.0 国际许可协议进行许可。
进一步分析数据,我们发现数据中还有不少的•和空格,我们使用replace方法去掉即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 pdf_page.page_content = pdf_page.page_content.replace("•" , "" ) pdf_page.page_content = pdf_page.page_content.replace(' ' , '' ) ---------------------------------------------------------------------------------------------- 前言“周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能 多的读者通过西瓜书对机器学习有所了解,所以在书中对部分公式的推导细节没有详述,但是这对那些想 深究公式推导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及 对部分公式补充具体的推导细节。”读到这里,大家可能会疑问为啥前面这段话加了引号,因为这只是我 们最初的遐想,后来我们了解到,周老师之所以省去这些推导细节的真实原因是,他本尊认为“理工科数 学基础扎实点的大二下学生应该对西瓜书中的推导细节无困难吧,要点在书里都有了,略去的细节应能 脑补或做练习”。所以......本南瓜书只能算是我等数学渣渣在自学的时候记下来的笔记,希望能够帮助 大家都成为一名合格的“理工科数学基础扎实点的大二下学生”。使用说明南瓜书的所有内容都是以西瓜 书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是以西瓜书为主线,遇到自己推导不出来 或者看不懂的公式时再来查阅南瓜书;对于初学机器学习的小白,西瓜书第1 章和第2 章的公式强烈不建 议深究,简单过一下即可,等你学得有点飘的时候再回来啃都来得及;每个公式的解析和推导我们都力(zhi)争(neng) 以本科数学基础的视角进行讲解,所以超纲的数学知识我们通常都会以附录和参考文献的 形式给出,感兴趣的同学可以继续沿着我们给的资料进行深入学习;若南瓜书里没有你想要查阅的公式 ,或者你发现南瓜书哪个地方有错误,请毫不犹豫地去我们GitHub的Issues(地址:https://github.coes); 配套视频教程:https://www.bilibili.com/video/BV1Mh411e7VU 在线阅读地址:https://datawhalechina.github.io/pumpkin-book(仅供第1 版)最新版PDF获取地址:https://github.com/datawhalechina/pumpkin-book/releases 编委会主编:Sm1les、archwalker、jbb0523编委:juxiao、Majingmin、 MrBigFan、shanry、Ye980226封面设计:构思-Sm1les、创作-林王茂盛致谢特别感谢awyd234、feijuan 、Ggmatch、Heitao5200、huaqing89、LongJH、LilRachel、LeoLRH、Nono17、spareribs、sunchaothu 、StevenLzq在最早期的时候对南瓜书所做的贡献。扫描下方二维码,然后回复关键词“南瓜书”,即可加 入“南瓜书读者交流群”版权声明本作品采用知识共享署名-非商业性使用-相同方式共享4.0 国际许可协议 进行许可。
文档分割 由于单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力,因此,在构建向量知识库的过程中,我们往往需要对文档进行分割,将单个文档按长度或者固定的规则分割成若干个chunk,然后每个 chunk 转化为词向量,存储到向量数据库中。
在检索时,我们会以 chunk 作为检索的元单位,也就是每一页检索到 k 个 chunk 作为模型可以参考来回答用户问题的知识,这个 k 是我们可以自由设定的
Langchain 中文本分割器都根据 chunk_size (块大小)和 chunk_overlap (块与块之间的重叠大小)进行分割。
chunk_size 指每个块包含的字符或Token(如单词、句子等)的数量chunk_overlap 指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息
Langchain 提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小
RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。CharacterTextSplitter(): 按字符来分割文本。MarkdownHeaderTextSplitter(): 基于指定的标题来分割markdown 文件。TokenTextSplitter(): 按token来分割文本。SentenceTransformersTokenTextSplitter(): 按token来分割文本Language(): 用于 CPP、Python、Ruby、Markdown 等。NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。SpacyTextSplitter(): 使用 Spacy按句子的切割文本。
为了便于后续的嵌入和检索,长文档被分割成较小的、可管理的文本块(chunks)。这里采用了递归字符分割策略,使用其默认参数进行分块。当不指定参数初始化 RecursiveCharacterTextSplitter() 时,其默认行为旨在最大程度保留文本的语义结构:
默认分隔符与语义保留 : 按顺序尝试使用一系列预设的分隔符 ["\n\n" (段落), "\n" (行), " " (空格), "" (字符)] 来递归分割文本。这种策略的目的是尽可能保持段落、句子和单词的完整性,因为它们通常是语义上最相关的文本单元,直到文本块达到目标大小。保留分隔符 : 默认情况下 (keep_separator=True),分隔符本身会被保留在分割后的文本块中。默认块大小与重叠 : 使用其基类 TextSplitter 中定义的默认参数 chunk_size=4000(块大小)和 chunk_overlap=200(块重叠)。这些参数确保文本块符合预定的大小限制,并通过重叠来减少上下文信息的丢失。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from langchain_text_splitters import RecursiveCharacterTextSplitterCHUNK_SIZE = 500 OVERLAP_SIZE = 50 ''' * RecursiveCharacterTextSplitter 递归字符文本分割 RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]), 这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置 RecursiveCharacterTextSplitter需要关注的是4个参数: * separators - 分隔符字符串数组 * chunk_size - 每个文档的字符数量限制 * chunk_overlap - 两份文档重叠区域的长度 * length_function - 长度计算函数 ''' text_splitter = RecursiveCharacterTextSplitter( chunk_size=CHUNK_SIZE, chunk_overlap=OVERLAP_SIZE, ) text_splitter.split_text(pdf_page.page_content[0 :1000 ]) split_docs = text_splitter.split_documents(pdf_pages) print (f"切分后的文件数量:{len (split_docs)} " )print (f"切分后的字符数(可以用来大致评估 token 数):{sum ([len (doc.page_content) for doc in split_docs])} " )------------------------------------------------------------------------------------------------------- 切分后的文件数量:712 切分后的字符数(可以用来大致评估 token 数):305745
搭建并使用向量数据库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import osfrom langchain_community.document_loaders import PyMuPDFLoaderfrom langchain_community.document_loaders import UnstructuredAPIFileIOLoaderfrom langchain_text_splitters import RecursiveCharacterTextSplitterfile_paths = [] folder_path = "D:\Amadeus\Zeztz-demo1\datas\knowledge_db" for root, dirs, files in os.walk(folder_path): for file in files: file_path = os.path.join(root, file) file_paths.append(file_path) print (file_paths)---------------------------------------------------------------------------------------------------------- ['D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\pumpkin_book.pdf' ]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 loaders = [] for file_path in file_paths: if file_path.endswith('.pdf' ): loaders.append(PyMuPDFLoader(file_path)) else : loaders.append(UnstructuredAPIFileIOLoader(file_path)) texts = [] for loader in loaders: texts.extend(loader.load()) text_splitter = RecursiveCharacterTextSplitter( chunk_size=500 , chunk_overlap=50 , ) split_docs = text_splitter.split_documents(texts)
构建Chroma向量库 Langchain 集成了超过 30 个不同的向量存储库。我们选择 Chroma 是因为它轻量级且数据存储在内存中,这使得它非常容易启动和开始使用。
这边使用阿里云所提供的 api 对获取embedding模型进行封装如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import osfrom typing import List from langchain_core.embeddings import Embeddingsapi_key=os.getenv("DASHSCOPE_API_KEY" ) base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" class TextV4Embeddings (Embeddings ): """使用text-embedding-v4模型""" def __init__ (self ): from openai import OpenAI self .client = OpenAI(api_key=api_key,base_url=base_url) def embed_documents (self, texts: List [str ] ) -> List [List [float ]]: """生成输入文本列表的embedding. Args: texts(List[str]):要生成embedding的文本列表. Returns:List[List[float]]:输入列表中每个文档的embedding列表。每个embedding都表示为一个浮点值列表。 """ completion = self .client.embeddings.create( model="text-embedding-v4" , input =texts, dimensions=1024 , encoding_format="float" ) return [embeddings.embedding for embeddings in completion.data] def embed_query (self, text: str ) -> list [float ]: completion = self .client.embeddings.create( model="text-embedding-v4" , input =text, dimensions=1024 , encoding_format="float" ) return completion.data[0 ].embedding
然后,使用封装好的嵌入模型去构建Chroma数据库
1 2 3 4 5 6 7 8 9 10 11 12 from demo_embedding import TextV4Embeddingsvectordb = Chroma.from_documents( documents=split_docs, embedding=TextV4Embeddings(), persist_directory="./data_base/vector_db" ) vectordb._collection.count() print (vectordb._collection.count())
创建好以后,可以直接调用已经创建好在本地的知识库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from demo_embedding import TextV4Embeddingsfrom langchain_community.vectorstores import Chromadef load_existing_chroma (): """加载本地已保存的Chroma知识库""" persist_path = os.path.abspath("./data_base/vector_db" ) print (f"正在加载知识库: {persist_path} " ) vectordb = Chroma( persist_directory=persist_path, embedding_function=TextV4Embeddings() ) count = vectordb._collection.count() print (f"知识库加载成功,包含 {count} 个文档" ) return vectordb
Chroma的相似度搜索使用的是余弦距离,即:
其中、$a_i、b_i$分别是向量$A$、$B$的分量。
当你需要数据库返回严谨的按余弦相似度排序的结果时可以使用similarity_search函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 def search_in_chroma (vectordb, query ): """在已加载的知识库中进行向量检索""" print (f"\n正在检索: {query} " ) results = vectordb.similarity_search( query=query, k=3 ) print (f"找到 {len (results)} 个相似结果:" ) for i, result in enumerate (results, 1 ): print (f"\n结果 {i} :" ) print (f"内容: {result.page_content[:200 ]} ..." ) print (f"元数据: {result.metadata} " ) return results vectordb = load_existing_chroma() query1 = "什么是大语言模型" search_in_chroma(vectordb, query1) ----------------------------------------------------------------------------------------------------- 正在加载知识库: D:\Amadeus\data_base\vector_db 知识库加载成功,包含 1992 个文档 正在检索: 什么是大语言模型 找到 3 个相似结果: 结果 1 : 内容: 第二章 语言模型,提问范式与 Token 在本章中,我们将和您分享大型语言模型(LLM)的工作原理、训练方式以及分词器(tokenizer)等细 节对 LLM 输出的影响。我们还将介绍 LLM 的提问范式(chat format ),这是一种指定系统消息 (system message)和用户消息(user message)的方式,让您了解如何利用这种能力。 一、语言模型 大语言模型(LLM... 元数据: {'subject' : '' , 'page' : 97 , 'file_path' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'creator' : '' , 'moddate' : '2023-08-17T06:20:22+00:00' , 'keywords' : '' , 'producer' : 'iLovePDF' , 'creationdate' : '' , 'modDate' : 'D:20230817062022Z' , 'author' : '' , 'total_pages' : 373 , 'creationDate' : '' , 'source' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'trapped' : '' , 'title' : '' , 'format' : 'PDF 1.7' } 结果 2 : 内容: 复训练促使模型参数收敛,使其预测能力不断提高。经过在海量文本数据集上的训练,语言模型 可以达 到十分准确地预测下一个词的效果。这种以预测下一个词为训练目标的方法使得语言模型获得强大的语 言生成能力。 大型语言模型主要可以分为两类:基础语言模型和指令调优语言模型。 基础语言模型(Base LLM)通过反复预测下一个词来训练的方式进行训练,没有明确的目标导向。因 此,如果给它一个开放式的 prompt ... 元数据: {'creationdate' : '' , 'page' : 97 , 'keywords' : '' , 'modDate' : 'D:20230817062022Z' , 'subject' : '' , 'creator' : '' , 'format' : 'PDF 1.7' , 'file_path' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'trapped' : '' , 'title' : '' , 'total_pages' : 373 , 'author' : '' , 'moddate' : '2023-08-17T06:20:22+00:00' , 'creationDate' : '' , 'producer' : 'iLovePDF' , 'source' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' }结果 3 : 内容: 执行特定的、通常是一次性的任务。但我们认为,对于开发人员,大语言模型(LLM) 的更强大 功能是 能通过 API 接口调用,从而快速构建软件应用程序。实际上,我们了解到 DeepLearning.AI 的姊妹公 司 AI Fund 的团队一直在与许多初创公司合作,将这些技术应用于诸多应用程序上。很兴奋能看到 LLM API 能够让开发人员非常快速地构建应用程序。 在本模块,我们将与读者分享提升大语... 元数据: {'file_path' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'creator' : '' , 'author' : '' , 'format' : 'PDF 1.7' , 'creationdate' : '' , 'moddate' : '2023-08-17T06:20:22+00:00' , 'creationDate' : '' , 'total_pages' : 373 , 'producer' : 'iLovePDF' , 'title' : '' , 'source' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'page' : 9 , 'modDate' : 'D:20230817062022Z' , 'keywords' : '' , 'subject' : '' , 'trapped' : '' }
可以使用similarity_search_with_score函数返回相似度分数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def search_with_score (vectordb, query ): """在已加载的知识库中进行向量检索,并返回相似度分数""" print (f"\n正在检索(带分数): {query} " ) results_with_scores = vectordb.similarity_search_with_score( query=query, k=3 ) print (f"找到 {len (results_with_scores)} 个相似结果:" ) for i, (result, score) in enumerate (results_with_scores, 1 ): print (f"\n结果 {i} (相似度: {score:.4 f} ):" ) print (f"内容: {result.page_content[:200 ]} ..." ) print (f"元数据: {result.metadata} " ) return results_with_scores vectordb = load_existing_chroma() query2 = "微调" search_with_score(vectordb, query2) ---------------------------------------正在加载知识库: D:\Amadeus\data_base\vector_db 知识库加载成功,包含 1992 个文档 正在检索(带分数): 微调 找到 3 个相似结果: 结果 1 (相似度: 0.8100 ): 内容: 并给出符合指令的回答。例如,对“中国的首都是哪里?”这个问题,经过微调的语言模型很可能 直接回答 “中国的首都是北京”,而不是生硬地列出一系列相关问题。指令微调使语言模型更加适合任务导向的对 话 应用。它可以生成遵循指令的语义准确的回复,而非自由联想。因此,许多实际应用已经采用指令调优 语言模型。熟练掌握指令微调的工作机制,是开发者实现语言模型应用的重要一步。 那么,如何将基础语言模型转变为指令微调语... 元数据: {'creationdate' : '' , 'page' : 97 , 'subject' : '' , 'creator' : '' , 'source' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'total_pages' : 373 , 'creationDate' : '' , 'modDate' : 'D:20230817062022Z' , 'author' : '' , 'format' : 'PDF 1.7' , 'keywords' : '' , 'file_path' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'producer' : 'iLovePDF' , 'trapped' : '' , 'title' : '' , 'moddate' : '2023-08-17T06:20:22+00:00' }结果 2 (相似度: 0.9288 ): 内容: 五、在难测试用例上评估修改后的指令 我们可以在之前表现不如预期的较难测试用例上评估改进后系统的效果: 六、回归测试:验证模型在以前的测试用例上仍然有效 检查并修复模型以提高难以测试的用例效果,同时确保此修正不会对先前的测试用例性能造成负面影 响。 [{'category' : '电脑和笔记本' , \ 'products' : ['TechPro 超极本' , 'BlueWave 游戏本' ...元数据: {'modDate' : 'D:20230817062022Z' , 'trapped' : '' , 'format' : 'PDF 1.7' , 'creator' : '' , 'keywords' : '' , 'title' : '' , 'file_path' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'total_pages' : 373 , 'creationDate' : '' , 'page' : 167 , 'subject' : '' , 'source' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'moddate' : '2023-08-17T06:20:22+00:00' , 'creationdate' : '' , 'author' : '' , 'producer' : 'iLovePDF' } 结果 3 (相似度: 0.9514 ): 内容: 图 1.7 温度系数 一般来说,如果需要可预测、可靠的输出,则将 temperature 设置为0 ,在所有课程中,我们一直设置 温度为零;如果需要更具创造性的多样文本,那么适当提高 temperature 则很有帮助。调整这个参数可 以灵活地控制语言模型的输出特性。 在下面例子中,针对同一段来信,我们提醒语言模型使用用户来信中的详细信息,并设置一个较高的 temperature ,运行两次,比较... 元数据: {'creationdate' : '' , 'producer' : 'iLovePDF' , 'author' : '' , 'total_pages' : 373 , 'creationDate' : '' , 'modDate' : 'D:20230817062022Z' , 'creator' : '' , 'moddate' : '2023-08-17T06:20:22+00:00' , 'source' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'keywords' : '' , 'title' : '' , 'subject' : '' , 'format' : 'PDF 1.7' , 'file_path' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'trapped' : '' , 'page' : 78 }--------------------------------------------------------------
如果只考虑检索出内容的相关性会导致内容过于单一,可能丢失重要信息。
最大边际相关性 (MMR, Maximum marginal relevance) 可以帮助我们在保持相关性的同时,增加内容的丰富度。
核心思想是在已经选择了一个相关性高的文档之后,再选择一个与已选文档相关性较低但是信息丰富的文档。这样可以在保持相关性的同时,增加内容的多样性,避免过于单一的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 def search_in_mmr (vectordb, query ): """在已加载的知识库中进行向量检索""" print (f"\n正在检索: {query} " ) results = vectordb.max_marginal_relevance_search( query=query, k=3 ) print (f"找到 {len (results)} 个相似结果:" ) for i, result in enumerate (results, 1 ): print (f"\n结果 {i} :" ) print (f"内容: {result.page_content[:200 ]} ..." ) print (f"元数据: {result.metadata} " ) return results vectordb = load_existing_mmr() query3 = "什么是大语言模型" search_in_chroma(vectordb, query3) ---------------------------------------------------------------------------------------------------- 正在加载知识库: D:\Amadeus\data_base\vector_db 知识库加载成功,包含 1992 个文档 正在检索: 什么是大语言模型 找到 3 个相似结果: 结果 1 : 内容: 第二章 语言模型,提问范式与 Token 在本章中,我们将和您分享大型语言模型(LLM)的工作原理、训练方式以及分词器(tokenizer)等细 节对 LLM 输出的影响。我们还将介绍 LLM 的提问范式(chat format ),这是一种指定系统消息 (system message)和用户消息(user message)的方式,让您了解如何利用这种能力。 一、语言模型 大语言模型(LLM... 元数据: {'title' : '' , 'creationdate' : '' , 'subject' : '' , 'creator' : '' , 'file_path' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'keywords' : '' , 'format' : 'PDF 1.7' , 'source' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'creationDate' : '' , 'page' : 97 , 'modDate' : 'D:20230817062022Z' , 'trapped' : '' , 'moddate' : '2023-08-17T06:20:22+00:00' , 'producer' : 'iLovePDF' , 'total_pages' : 373 , 'author' : '' } 结果 2 : 内容: 三、局限性 开发大模型相关应用时请务必铭记: 虚假知识:模型偶尔会生成一些看似真实实则编造的知识 在开发与应用语言模型时,需要注意它们可能生成虚假信息的风险。尽管模型经过大规模预训练,掌握 了丰富知识,但它实际上并没有完全记住所见的信息,难以准确判断自己的知识边界,可能做出错误推 断。若让语言模型描述一个不存在的产品,它可能会自行构造出似是而非的细节。这被称为“幻觉” (Hallucinati... 元数据: {'format' : 'PDF 1.7' , 'file_path' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'creationdate' : '' , 'creationDate' : '' , 'keywords' : '' , 'modDate' : 'D:20230817062022Z' , 'producer' : 'iLovePDF' , 'source' : 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf' , 'title' : '' , 'total_pages' : 373 , 'moddate' : '2023-08-17T06:20:22+00:00' , 'trapped' : '' , 'page' : 18 , 'creator' : '' , 'author' : '' , 'subject' : '' } 结果 3 : 内容: 下面是一个使用大语言模型进行语法纠错的简单示例,类似于Grammarly(一个语法纠正和校对的 工 具)的功能。 输入一段关于熊猫玩偶的评价文字,语言模型会自动校对文本中的语法错误,输出修改后的正确版本。 这里使用的Prompt比较简单直接,只要求进行语法纠正。我们也可以通过扩展Prompt,同时请求语言 模型调整文本的语气、行文风格等。 text = [ "The girl with the... 元数据: {'format': 'PDF 1.7', 'page': 66, 'creator': '', 'subject': '', 'keywords': '', 'trapped': '', 'creationDate': '', 'producer': 'iLovePDF', 'moddate': '2023-08-17T06:20:22+00:00', 'total_pages': 373, 'author': '', 'file_path': 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf', 'source': 'D:\\Amadeus\\Zeztz-demo1\\datas\\knowledge_db\\LLM-v1.0.0.pdf', 'creationdate': '', 'title': '', 'modDate': 'D:20230817062022Z'}
构建RAG应用 构建检索问答链 在上面的章节当中,我们已经介绍了如何根据自己的本地知识文档,搭建一个向量知识库。 在接下来的内容里,我们将使用搭建好的向量数据库,对 query 查询问题进行召回,并将召回结果和 query 结合起来构建 prompt,输入到大模型中进行问答。
对于已经加载的向量数据库,我们可以通过as_retriever方法把向量数据库构造成检索器。我们使用一个问题 query 进行向量检索。
如下代码会在向量数据库中根据相似性进行检索,返回前k个最相似的文档。
1 2 3 4 query4 = "微调有哪些方法" retriever = vectordb.as_retriever(search_kwargs={"k" : 3 }) docs = retriever.invoke(query4) print (f"检索到的内容数:{len (docs)} " )
打印一下检索到的内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 for i, doc in enumerate (docs): print (f"检索到的第{i} 个内容: \n {doc.page_content} " , end="\n-----------------------------------------------------\n" ) ---------------------------------------------------------------------------------------------------------- 检索到的第0 个内容: 并给出符合指令的回答。例如,对“中国的首都是哪里?”这个问题,经过微调的语言模型很可能直接回 答 “中国的首都是北京”,而不是生硬地列出一系列相关问题。指令微调使语言模型更加适合任务导向的对 话 应用。它可以生成遵循指令的语义准确的回复,而非自由联想。因此,许多实际应用已经采用指令调优 语言模型。熟练掌握指令微调的工作机制,是开发者实现语言模型应用的重要一步。 那么,如何将基础语言模型转变为指令微调语言模型呢? 这也就是训练一个指令微调语言模型(例如ChatGPT)的过程。 首先,在大规模文本数据集上进行无监督预训练,获得基础语言模型。这一步需要使用数千亿词甚至更 多的数据,在大型超级计算系统上可能需要数月时间。 之后,使用包含指令及对应回复示例的小数据集对基础模型进行有监督 fine-tune,这让模型逐步学会 遵循指令生成输出,可以通过雇佣承包商构造适合的训练示例。 接下来,为了提高语言模型输出的质量,常见的方法是让人类对许多不同输出进行评级,例如是否有 用、是否真实、是否无害等。 然后,您可以进一步调整语言模型,增加生成高评级输出的概率。这通常使用基于人类反馈的强化学习 ----------------------------------------------------- 检索到的第1 个内容: 五、在难测试用例上评估修改后的指令 我们可以在之前表现不如预期的较难测试用例上评估改进后系统的效果: 六、回归测试:验证模型在以前的测试用例上仍然有效 检查并修复模型以提高难以测试的用例效果,同时确保此修正不会对先前的测试用例性能造成负面影 响。 [{'category' : '电脑和笔记本' , \ 'products' : ['TechPro 超极本' , 'BlueWave 游戏本' , 'PowerLite Convertible' , 'TechPro Desktop' , 'BlueWave Chromebook' ]}] """ few_shot_user_2 = """ 我想要最便宜的电脑。你推荐哪款?""" few_shot_assistant_2 = """ [{'category' : '电脑和笔记本' , \ 'products' : ['TechPro 超极本' , 'BlueWave 游戏本' , 'PowerLite Convertible' , 'TechPro ----------------------------------------------------- 检索到的第2个内容: 图 1.7 温度系数 一般来说,如果需要可预测、可靠的输出,则将 temperature 设置为0,在所有课程中,我们一直设置 温度为零;如果需要更具创造性的多样文本,那么适当提高 temperature 则很有帮助。调整这个参数可 以灵活地控制语言模型的输出特性。 ' products': [' TechPro 超极本', ' BlueWave 游戏本', ' PowerLite Convertible', ' TechPro ----------------------------------------------------- 检索到的第2 个内容: 图 1.7 温度系数 一般来说,如果需要可预测、可靠的输出,则将 temperature 设置为0 ,在所有课程中,我们一直设置 温度为零;如果需要更具创造性的多样文本,那么适当提高 temperature 则很有帮助。调整这个参数可 以灵活地控制语言模型的输出特性。 温度为零;如果需要更具创造性的多样文本,那么适当提高 temperature 则很有帮助。调整这个参数可 以灵活地控制语言模型的输出特性。 以灵活地控制语言模型的输出特性。 在下面例子中,针对同一段来信,我们提醒语言模型使用用户来信中的详细信息,并设置一个较高的 temperature ,运行两次,比较他们的结果有何差异。 prompt = f""" 你是一名客户服务的AI助手。 你的任务是给一位重要的客户发送邮件回复。 根据通过“```”分隔的客户电子邮件生成回复,以感谢客户的评价。 如果情感是积极的或中性的,感谢他们的评价。 如果情感是消极的,道歉并建议他们联系客户服务。 请确保使用评论中的具体细节。 以简明和专业的语气写信。 以“AI客户代理”的名义签署电子邮件。 客户评价:```{review} ``` 评论情感:{sentiment} """
创建检索链:
将检索到的多个文本块的页面内容 (doc.page_content) 合并成一个单一的字符串,并使用双换行符 ("\n\n") 分隔各个块,形成最终的上下文信息 (docs_content) 供大语言模型参考。
1 2 3 4 5 6 7 8 9 10 from langchain_core.runnables import RunnableLambdadef combine_docs (docs ): return "\n\n" .join(doc.page_content for doc in docs) combiner = RunnableLambda(combine_docs) retrieval_chain = retriever | combiner retrieval_chain.invoke("南瓜书是什么?" ) ----------------------------------------------------------------------------------------------------- '前言\n“周志华老师的《机器学习》(西瓜书)是机器学习领域的经典入门教材之一,周老师为了使尽可能多的读\n者通过西瓜书对机器学习有所了解, 所以在书中对部分公式的推导细节没有详述,但是这对那些想深究公式推\n导细节的读者来说可能“不太友好”,本书旨在对西瓜书里比较难理解的公式加以解析,以及对部分公式补充\n具体的推导细节。”\n读到这里,大家可能会疑问为啥前面这段话加了引号,因为这只是我们最初的遐想,后来我们了解到,周\n老师之所以省去这些推导细节的真实原因是,他本尊认为“理工科数学基础扎实点的大二下学生应该对西瓜书\n中的推导细节无困难吧,要点在书里都有了,略去的细节应能脑补或做练习”。所以...... 本南瓜书只能算是我\n等数学渣渣在自学的时候记下来的笔记,希望能够帮助大家都成为一名合格的“理工科数学基础扎实点的大二\n下学生”。\n使用说明\n• 南瓜书的所有内容都是以西瓜书的内容为前置知识进行表述的,所以南瓜书的最佳使用方法是以西瓜书\n为主线,遇到自己推导不出来或者看不懂的公式时再来查阅南瓜书;\n• 对于初学机器学习的小白,西瓜书第1 章和第2 章的公式强烈不建议深究,简单过一下即可,等你学得\n\n最新版PDF 获取地址:https://github.com/datawhalechina/pumpkin-book/releases\n编委会\n主编:Sm1les、archwalker、jbb0523\n编委:juxiao、Majingmin、MrBigFan、shanry、Ye980226\n封面设计:构思-Sm1les、创作-林王茂盛\n致谢\n特别感谢awyd234、feijuan、Ggmatch、Heitao5200、huaqing89、LongJH、LilRachel、LeoLRH、Nono17、\nspareribs、sunchaothu、StevenLzq 在最早期的时候对南瓜书所做的贡献。\n扫描下方二维码,然后回复关键词“南瓜书”,即可加入“南瓜书读者交流群”\n版权声明\n本作品采用知识共享署名-非商业性使用-相同方式共享4.0 国际许可协议进行许可。\n\n• 对于初学机器学习的小白,西瓜书第1 章和第2 章的公式强烈不建议深究,简单过一下即可,等你学得\n有点飘的时候再回来啃都来得及;\n• 每个公式的解析和推导我们都力(zhi) 争(neng) 以本科数学基础的视角进行讲解,所以超纲的数学知识\n我们通常都会以附录和参考文献的形式给出,感兴趣的同学可以继续沿着我们给的资料进行深入学习;\n• 若南瓜书里没有你想要查阅的公式,或者你发现南瓜书哪个地方有错误,请毫不犹豫地去我们GitHub 的\nIssues(地址:https://github.com/datawhalechina/pumpkin-book/issues)进行反馈,在对应版块\n提交你希望补充的公式编号或者勘误信息,我们通常会在24 小时以内给您回复,超过24 小时未回复的\n话可以微信联系我们(微信号:at-Sm1les);\n配套视频教程:https://www.bilibili.com/video/BV1Mh411e7VU\n在线阅读地址:https://datawhalechina.github.io/pumpkin-book(仅供第1 版)'
使用 "\n\n" (双换行符) 而不是 "\n" (单换行符) 来连接不同的检索文档块,主要是为了在传递给大型语言模型(LLM)时,能够更清晰地在语义上区分这些独立的文本片段。双换行符通常代表段落的结束和新段落的开始,这种格式有助于LLM将每个块视为一个独立的上下文来源,从而更好地理解和利用这些信息来生成回答。
LCEL中要求所有的组成元素都是Runnable类型,前面我们见过的ChatModel、PromptTemplate等都是继承自Runnable类。上方的retrieval_chain是由检索器retriever及组合器combiner组成的,由|符号串连,数据从左向右传递,即问题先被retriever检索得到检索结果,再被combiner进一步处理并输出。
创建LLM:
在这里,我们调用 阿里云 的 API 创建一个LLM,当然你也可以使用其他 LLM 的API 进行创建。
1 2 3 4 5 6 7 8 9 from langchain_openai import ChatOpenAIllm = ChatOpenAI( api_key="aliyun_api_key" , model_name="qwen3-max" , base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" , ) print (llm.invoke("你好" ).content)
构建检索问答链:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from langchain_core.prompts import PromptTemplatefrom langchain_core.runnables import RunnablePassthrough, RunnableParallelfrom langchain_core.output_parsers import StrOutputParsertemplate = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答 案。最多使用三句话。尽量使答案简明扼要。请你在回答的最后说“谢谢你的提问!”。 {context} 问题: {input} """ prompt = PromptTemplate(template=template) qa_chain = ( RunnableParallel({"context" : retrieval_chain, "input" : RunnablePassthrough()}) | prompt | llm | StrOutputParser() )
在上边代码中我们把刚才定义的检索链当作子链作为prompt的context,再使用RunnablePassthrough存储用户的问题作为prompt的input。又因为这两个操作是并行的,所以我们使用RunnableParallel来将他们并行运行。
检索问答链效果测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 question_1 = "什么是判别式模型?" result = qa_chain.invoke(question_1) print ("大模型+知识库后回答 question_1 的结果:" )print (result)print ("------------------------------------------------------------------------\n" )print ("大模型自己的回答question_1:" )print (llm.invoke(question_1).content)---------------------------------------------------------------------------------------------------------- 大模型+知识库后回答 question_1 的结果: 判别式模型是直接求解条件概率 \( P(y|x) \) 的模型,即在已知输入特征 \( x \) 的条件下预测输出 变量 \( y \)。它不关心样本的联合分布,而是专注于区分不同类别的边界。常见的判别式模型包括对 数几率回归、支持向量机等。 ------------------------------------------------------------------------ 大模型自己的回答question_1: **判别式模型**(Discriminative Model)是机器学习中的一类模型,其主要目标是直接对**条件概率 分布 \( P(y|x) \)** 建模,即在给定输入 \( x \) 的情况下预测输出 \( y \)。换句话说,判别式模 型关注的是“在看到输入数据后,如何最好地区分或判断其所属类别”。 判别式模型不关心数据是如何生成的,它不建模输入 \( x \) 的分布,而是专注于学习输入与输出之间 的边界或映射关系。 --- 假设我们要做图像分类:判断一张图片是猫还是狗。 - 判别式模型会直接学习: “给定这张图片的像素值,它是猫的概率是多少?” 即建模 \( P(\text{类别} | \text{图像}) \) --- 1. **逻辑回归**(Logistic Regression)2. **支持向量机**(SVM)3. **神经网络**(Neural Networks)4. **条件随机场**(CRF)5. **决策树、随机森林、梯度提升树**(如 XGBoost)--- | 特性 | 判别式模型 | 生成式模型 | |------|------------|-------------| | 建模目标 | \( P(y|x) \) | \( P(x, y) = P(x|y)P(y) \) | | 是否建模输入分布 | 否 | 是(建模 \( P(x|y) \)) | | 关注点 | 决策边界 | 数据生成过程 | | 典型例子 | SVM, Logistic Regression | 朴素贝叶斯、高斯混合模型、HMM | | 训练效率 | 通常更高 | 可能更复杂 | | 所需数据量 | 相对较少 | 通常需要更多数据 | --- - 通常在分类任务上表现更好,尤其是在有大量数据时。 - 更直接地优化分类性能。 - 模型结构相对简单,训练效率高。 - 无法生成新的数据样本(因为没有建模 \( P(x|y) \))。 - 对异常值或未见过的数据类型鲁棒性可能较差。 --- 判别式模型是一种“知其然,不必知其所以然”的方法——它不关心数据是怎么来的,只关心如何根据输入 做出最准确的判断。因此,在大多数监督学习任务(如分类、回归)中,判别式模型被广泛使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 question_2 = "Inception是什么" result = qa_chain.invoke(question_2) print ("大模型+知识库后回答 question_2 的结果:" )print (result)print ("------------------------------------------------------------------------\n" )print ("大模型自己的回答question_2:" )print (llm.invoke(question_2).content)--------------------------------------------------------------------------------------------------------- 大模型+知识库后回答 question_2 的结果: Inception 是一种深度卷积神经网络架构,其核心思想是使用 Inception 模块——在一个层中并行使用多种尺寸的卷积(如 1 ×1 、3 ×3 、5 ×5 )和池化操作,然后将结果拼接在一起。这种设计可以提高模型的表达能力,同时通过 1 ×1 卷积减少计算量。Inception V3 是该系列中的一个经典版本,常用于图 像分类和 DeepDream 等任务。 大模型自己的回答question_2: “Inception”(中文常译为《盗梦空间》)是由克里斯托弗·诺兰(Christopher Nolan)执导、编剧并监制的一部科幻悬疑电影,于2010 年上映。影片融合了动作、心理、哲学与视觉特效等多种元素,因其复杂的叙事结构和对梦境与现实界限的探讨而广受赞誉。 影片讲述了一群“盗梦者”(Extractors)通过进入他人梦境来窃取潜意识中的秘密。主角多米尼克·柯布(由莱昂纳多·迪卡普里奥饰演)是一位技艺高 超的盗梦者,但因被指控谋杀妻子而流亡海外。他获得了一个看似不可能完成的任务:不是窃取思想,而是“植入”一个想法(即“inception”,意为“植 入”或“开端”)。如果成功,他将能洗清罪名,重返家园。 为了完成任务,柯布组建了一支专业团队,深入目标人物罗伯特·费舍尔的多层梦境中,逐层构建梦境世界。然而,随着梦境层数加深,现实与幻想的界限逐渐模糊,柯布也必须面对自己内心深处关于亡妻玛尔(Mal)的执念与愧疚。 - **梦境共享**:通过特殊设备,多人可以进入同一个梦境。 - **梦境层级**:梦境可以嵌套,形成“梦中梦”,甚至多层嵌套。 - **时间膨胀**:越深的梦境,时间流逝越慢(例如现实中5 分钟,第一层梦境可能是1 小时,第二层是数天等)。 - **图腾(Totem)**:每个盗梦者都有一个私密物品,用于判断自己是否处于梦境中(如柯布的陀螺)。 - **潜意识防御**:梦境中的潜意识会以武装投影等形式攻击入侵者。 - 现实与虚幻的界限 - 记忆、悔恨与救赎 - 意识的可塑性与思想的植入 - 自我欺骗与执念 - 《Inception》获得了广泛好评,全球票房超过8 亿美元。 - 获得第83 届奥斯卡金像奖最佳摄影、最佳音效剪辑、最佳混音和最佳视觉效果四项大奖。 - 其开放式结局(陀螺是否停下)引发大量讨论,成为影史经典谜题之一。 此外,“Inception”一词本身在英语中意为“开始”或“起源”,在电影中特指“在他人潜意识中植入一个想法”的行为,这也是全片的核心设定。
向检索链添加聊天记录:
现在我们已经实现了通过上传本地知识文档,然后将他们保存到向量知识库,通过将查询问题与向量知识库的召回结果进行结合输入到 LLM 中,我们就得到了一个相比于直接让 LLM 回答要好得多的结果。在与语言模型交互时,你可能已经注意到一个关键问题 - 它们并不记得你之前的交流内容 。这在我们构建一些应用程序(如聊天机器人)的时候,带来了很大的挑战,使得对话似乎缺乏真正的连续性。这个问题该如何解决呢?
在本节中我们将使用 LangChain 中的ChatPromptTemplate,即将先前的对话嵌入到语言模型中,使其具有连续对话的能力。 ChatPromptTemplate可以接收聊天消息历史记录,这些历史记录将在回答问题时与问题一起传递给聊天机器人,从而将它们添加到上下文中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from langchain_core.prompts import ChatPromptTemplatesystem_prompt = ( "你是一个问答任务的助手。 " "请使用检索到的上下文片段回答这个问题。 " "如果你不知道答案就说不知道。 " "请使用简洁的话语回答用户。" "\n\n" "{context}" ) qa_prompt = ChatPromptTemplate( [ ("system" , system_prompt), ("placeholder" , "{chat_history}" ), ("human" , "{input}" ), ] )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 messages = qa_prompt.invoke( { "input" : "南瓜书是什么?" , "chat_history" : [], "context" : "" } ) for message in messages.messages: print (message.content) ----------------------------------------------------------------------------------------------------- 你是一个问答任务的助手。 请使用检索到的上下文片段回答这个问题。 如果你不知道答案就说不知道。 请使用简洁的话语回答用户。 南瓜书是什么?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 messages = qa_prompt.invoke( { "input" : "你可以介绍一下他吗?" , "chat_history" : [ ("human" , "西瓜书是什么?" ), ("ai" , "西瓜书是指周志华老师的《机器学习》一书,是机器学习领域的经典入门教材之一。" ), ], "context" : "" } ) for message in messages.messages: print (message.content) --------------------------------------------------------------------------------------------------------- 你是一个问答任务的助手。 请使用检索到的上下文片段回答这个问题。 如果你不知道答案就说不知道。 请使用简洁的话语回答用户。 西瓜书是什么? 西瓜书是指周志华老师的《机器学习》一书,是机器学习领域的经典入门教材之一。 你可以介绍一下他吗?
带有信息压缩的检索链:
因为我们正在搭建的问答链带有支持多轮对话功能,所以与单轮对话的问答链相比会多面临像上方输出结果的问题,即用户最新的对话语义不全,在使用用户问题查询向量数据库时很难检索到相关信息。像上方的“你可以介绍一下他吗?”,其实是“你可以介绍下周志华老师吗?”的意思。为了解决这个问题我们将采取信息压缩的方式,让llm根据历史记录完善用户的问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from langchain_core.runnables import RunnableBranchcondense_question_system_template = ( "请根据聊天记录完善用户最新的问题," "如果用户最新的问题不需要完善则返回用户的问题。" ) condense_question_prompt = ChatPromptTemplate([ ("system" , condense_question_system_template), ("placeholder" , "{chat_history}" ), ("human" , "{input}" ), ]) retrieve_docs = RunnableBranch( (lambda x: not x.get("chat_history" , False ), (lambda x: x["input" ]) | retriever, ), condense_question_prompt | llm | StrOutputParser() | retriever, )
支持聊天记录的检索问答链
这里我们使用之前定义的问答模板即qa_prompt构造问答链,另外我们通过RunnablePassthrough.assign将中间的查询结果存为"context",将最终结果存为"answer"。因为查询结果被存为"context",所以我们整合查询结果的函数combine_docs也要做相应的改动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def combine_docs (docs ): return "\n\n" .join(doc.page_content for doc in docs["context" ]) qa_chain = ( RunnablePassthrough.assign(context=combine_docs) | qa_prompt | llm | StrOutputParser() ) qa_history_chain = RunnablePassthrough.assign( context = (lambda x: x) | retrieve_docs ).assign(answer=qa_chain)
测试检索问答链
1 2 3 4 5 6 7 qa_history_chain.invoke({ "input" : "西瓜书是什么?" , "chat_history" : [] }) --------------------------------------------------------------------------------------------------------- 西瓜书是周志华老师所著的《机器学习》一书的昵称,它是机器学习领域的经典入门教材之一。
1 2 3 4 5 6 7 8 9 10 11 12 qa_history_chain.invoke({ "input" : "南瓜书跟它有什么关系?" , "chat_history" : [ ("human" , "西瓜书是什么?" ), ("ai" , "西瓜书是指周志华老师的《机器学习》一书,是机器学习领域的经典入门教材之一。" ), ] }) -------------------------------------------------------------------------------------------------------- 南瓜书是《机器学习公式详解》的别称,它是对周志华老师《机器学习》(西瓜书)中公式推导的补充 和解析,旨在帮助读者理解西瓜书中省略的数学细节。南瓜书以西瓜书的内容为基础,为初学者提供更 详细的公式推导过程,适合在阅读西瓜书遇到困难时对照学习。
可以看到,LLM 准确地判断了“它”是什么,代表着我们成功地传递给了它历史信息。另外召回的内容也有着问题的答案,证明我们的信息压缩策略也起到了作用。这种关联前后问题及压缩信息并检索的能力,可大大增强问答系统的连续性和智能水平。