RAG实战,相关解析:
参考:18种RAG技术实战对比:从简单RAG到自适应RAG全面解析 | ApFramework
参考:Implementation of all RAG techniques in a simpler way
从最基础的RAG实现开始,理解其工作原理并评估其效果:
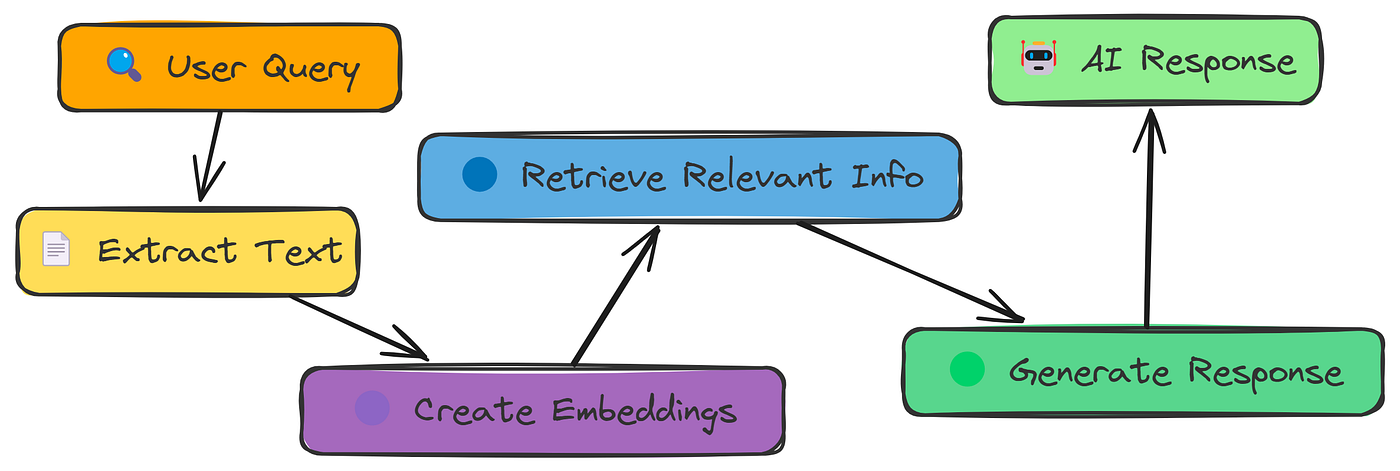
如图所示,简单RAG管道的工作原理如下:
- 从PDF中提取文本。
- 将文本分成更小块
- 将块转换为数字嵌入
- 根据查询搜索最相关的块
- 使用检索到的块生成响应
- 将答案与正确答案进行比较以评估准确性
首先,让我们加载文档,获取文本,并将其分成可管理的块:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| class DataPreparationModule:
"""数据准备模块 - 负责数据加载、清洗和预处理"""
def __init__(self, data_path: str):
self.data_path = data_path
self.documents: List[Document] = []
self.chunks: List[Document] = []
self.parent_child_map: Dict[str, List[str]] = {}
def load_documents(self) -> List[Document]:
"""批量加载文档数据"""
documents = []
data_path = Path(self.data_path)
print("验证数据路径:", data_path)
for file_path in tqdm(list(data_path.rglob("*.pdf")), desc="加载文档"):
loader = PyMuPDFLoader(str(file_path))
loaded_docs = loader.load()
parent_id = str(uuid.uuid4())
if loaded_docs:
merged_content = ""
for doc in loaded_docs:
merged_content += doc.page_content + "\n\n"
doc = Document(
page_content=merged_content,
metadata={
"source": str(file_path),
"parent_id": parent_id,
"doc_type": "parent",
}
)
documents.append(doc)
print(f"总共加载了 {len(documents)} 个文档")
self.documents = documents
return documents
def chunk_documents(self) -> List[Document]:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
)
split_docs = text_splitter.split_documents(self.documents)
return split_docs
|
接下来,我们需要将 split_docs 进行模型嵌入到本地数据库当中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def IndexConstruction(self, persist_path):
"""索引构建,并构建数据库"""
split_docs = self.chunk_documents()
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=TextV4Embeddings(),
persist_directory=persist_path
)
vectordb.persist()
count = vectordb._collection.count()
print(f"数据库中文档数量: {count}")
if os.path.exists(persist_path):
print(f"持久化目录已创建: {persist_path}")
files = os.listdir(persist_path)
print(f"目录内容: {files}")
else:
print(f"持久化目录创建失败: {persist_path}")
|
这里的embedding换成自己所用的嵌入模型,persist_path 是数据库保存的地址。
现在,我们可以执行 semantic_search





