
哈基鹏的大模型之旅(五)
大模型压测
LLM的压力测试(压测)是评估模型在高负载条件下性能和稳定性的关键方法。压测的目标是模拟实际使用场景中的高并发请求,检测系统的极限、潜在瓶颈和稳定性的问题,以确保模型在生产环境中能够稳定高效地运行。大模型的压测指标需结合 LLM特有指标(生成式任务的推理特性) 和 通用性能指标(反映系统整体承载能力) 综合分析。
LLM特有指标
吐字率(平均输出 token 速率/s)
大模型问答多为流式输出的交互形式,系统不会等模型把答案都计算完毕才返回给用户,而是模型计算出一个 token 就会返回给用户一个 token(有些系统可能也会有合并若干个 token 然后输出给用户),这是因为模型思考的时间通常都会很长,如果不及时给反馈就会流失用户。所以在这种交互模式下,模型每秒钟能返回给用户多少个 token 就成为了一个非常重要的性能指标。单位时间内计算出的 token 越多,就证明模型的计算性能更好。现在一般的大模型都会要求在某些并发下不低于 20/s 的吐字速率。
TTFT(Time To First Token,首字时间)
定义:从客户端发送完整请求(含prompt参数)到接收到模型生成的第一个token的时间间隔,单位为毫秒(ms)或秒(s)。
重要性:直接影响用户对“响应速度”的初始感知。在交互式场景(如对话、实时问答)中,TTFT过长(如超过2秒)会让用户产生“系统卡顿”的负面体验,甚至放弃使用。例如,用户问“今天天气怎么样?”,若TTFT为1秒,用户会觉得“响应快”;若TTFT为5秒,则可能认为“系统慢”。
token:
Token,也可以翻译为词,大模型理解人类语言是一个词一个词去理解的,而不是一个字一个字的理解。当一段文本到来的时候,系统需要先通过**”分词器”(tokenizer)**把一个句子分成一个一个的词去理解,分词器有一张词表,词表中的每个词都有自己的ID,而模型就是通过这些id来区分这些词的。另外,标点符号也可能是词。
比如在 “我喜欢篮球,也喜欢 RAP” 这句话中,“逗号” 是一个 token,“喜欢” 是一个 token,“我” 是一个 token,“RAP” 中 “R” 可能是个独立的 token,“A” 也可能是个独立的 token,而 “RAP” 合起来也可能是个独立的 token,这就要看不同的分词器中,那张词表是怎么定义的。
TPOT(Time Per Output Token,每token输出时间)
定义:生成过程中,相邻两个token之间的平均时间间隔,单位为毫秒/tokens(ms、token)。例如,生成第2个token与第1个token间隔50ms,第3个与第2个间隔60ms,则TPOT为(50+60)/2=55ms/token。
重要性:反映生成内容的“流畅性”。TPOT越高,用户感知的“卡顿感”越强(如生成一段100字的文本,若TPOT=100ms/token,需10秒完成,用户会觉得“断断续续”;若TPOT=30ms/token,需3秒完成,则体验流畅)。
TPS(Token Per Second,每秒传输token数)
定义:单位时间内(通常为秒)模型生成的总token数量,单位为token/s(tok/s)。
重要性:综合反映模型的生成效率,是衡量大模型服务“处理能力”的核心指标。对于长文本生成任务(如文档摘要、代码生成、报告撰写),TPS直接决定任务完成时间(如生成1000 token,TPS=100 tok/s需10秒,TPS=50 tok/s需20秒)。
通用性能指标
响应时间分布(p50、p95、p99)
定义: 响应时间指从客户端发送请求到接受到完整回复(最后一个token)的时间间隔。 响应时间分布通过分位数反映不同比例请求的响应表现:
p50(中位数): 50%的请求响应时间小于等于该值,反映”典型用户“的体验
p95: 95%的请求响应时间小于等于该值,反映“大部分用户”的体验(避免长尾问题掩盖);
p99: 99%的请求响应时间小于等于该值,反映“极端情况”下的性能(如高并发、复杂输入)。
重要性:平均响应时间可能被极端值扭曲(如1个请求100秒,99个请求1秒,平均为2秒,但p99=100秒),而分位数能更真实反映用户体验。例如,若p95=2秒,说明95%的用户在2秒内得到完整回复,服务可用性高;若p99=10秒,说明1%的用户需等待10秒,可能存在长尾瓶颈(如垃圾回收、资源竞争)。
每秒请求数(QPS,Queries Per Second)
定义:单位时间内(通常位秒)服务成功处理的请求数量,单位为req/s。
重要性:反映服务的并发处理能力,是衡量“服务能同时支持多少用户”的核心指标。例如,若QPS=100,说明每秒能处理100个用户请求;若预期用户峰值=1000,则需扩容至QPS≥1000。
错误率(Error Rate)
定义:单位时间内错误请求数占总请求数的比例,单位为百分比(%)。错误类型包括:
- HTTP状态码错误: 5xx(服务端错误,如500 Internal Server Error、502 Bad Gateway)、4xx(客户端错误,如400 Bad Request、413 Payload Too Large);
- 业务逻辑错误: 模型推理失败(如输入长度超过模型限制,输出格式不符合要求)、超时错误(请求处理时间超过阔值,如30秒)
- 资源错误: 内存溢出(OOM,Out of Memory)、GPU显存不足(CUDA out of memory)。
重要性:直接反映服务的稳定性。高错误率(如超过1%)会导致用户体验急剧下降(如频繁报错、请求失败),甚至影响业务可用性(如客服机器人无法回复用户)。
吞吐量(Throught)
定义:单位时间内系统处理的工作量,需结合任务类型定义:
- 生成式任务: 通常用“每秒生成token数”(即TPS)作为吞吐量,反映内容生成效率;
- 判别式任务(如文本分类、命名实体识别): 用“每秒处理样本数”(Sample/s)作为吞吐量,反映分类/标注效率;
- 通用场景: 也可用“每秒处理数据量”(如MB/s)反映数据传输或处理能力。
重要性:与QPS互补,QPS反映“请求数量”,吞吐量反映“实际完成的工作量”。例如,两个服务的QPS均为100,但服务A每个请求生成10 token(吞吐量=1000 tok/s),服务B每个请求生成100 token(吞吐量=10000 tok/s),则服务B的实际处理能力更强。
资源利用率(CPU、内存、网络)
定义:系统资源的使用程度,核心指标包括:
- CPU利用率: CPU处理任务的时间占比,分为“用户态利用率”(用户程序占用)和“内核态利用率”(系统调用占用);
- 内存利用率: 内存使用量占总内存的比例,需关注“已用内存”(包括缓存和缓冲区)和“可用内存”;
- GPU利用率: GPU计算单元的使用时间占比(通过
nvidia-smi查看),反映GPU的计算负载; - 网络带宽利用率: 网络输入/输出流量占总带宽的比例(如1Gbps网卡使用了500Mbps,则利用率为50%)。
因此,压测的核心目标是:
- 评估LLM在不同并发请求下的吞吐能力(QPS)和延迟表现(平均、P99);
- 测量模型的Token生成速度(TPS)以及首Token响应时间(TTFT);
- 判断系统是否达到性能瓶颈,确定最佳并发配置;
- 输出统一结构化的压测报告,支持图表,表格展示。
大模型压测工具选择与功能对比
业界主流大模型压测工具可分为三类:专用评测框架、通用性能测试工具和分布式评测系统。三类工具各有侧重,组合使用可实现全面评估。
EvalScope
EvalScope作为ModelScope官方推出的评测框架,其核心优势在于模型能力评估与基准测试。它支持70+个评测数据集和40万题的模型评测方案,覆盖语言、知识、推理、考试、理解、长文本、安全和代码等多维度。EvalScope的perf压测模块提供多维度负载模拟能力,支持并发数、请求量和prompt长度等关键参数的灵活配置。EvalScope特别适合测试模型在特定任务上的准确率、有害性等能力指标,并能通过可视化报告直观展示测试结果。
OpenCompass
OpenCompass(司南评测体系)则提供一站式评测平台,支持多模态大模型的全面评估。它包含CompassRank评测榜单、CompassHub基准社区和CompassKit工具链三大模块,覆盖12个一级能力维度和50余个二级能力维度。OpenCompass的分布式评测能力尤为突出,一行命令即可实现任务分割和分布式评测,数小时即可完成千亿模型全量评测。它还支持自定义垂直领域数据集(如LawBench、MedBench),为特定行业应用场景提供评测支持。
Locust
Locust作为通用性能测试工具,专注于HTTP协议的负载测试。它的最大优势在于用简单的Python代码定义测试场景,并提供实时Web UI界面监控吞吐量、响应时间和错误情况。Locust采用协程(gevent)机制实现并发,即使单台压力机也能模拟数千并发用户,适合测试大模型API接口的系统级性能。
大模型推理的原理
首先,我们需要知道大模型是怎么回答用户的问题的,看下面的图:
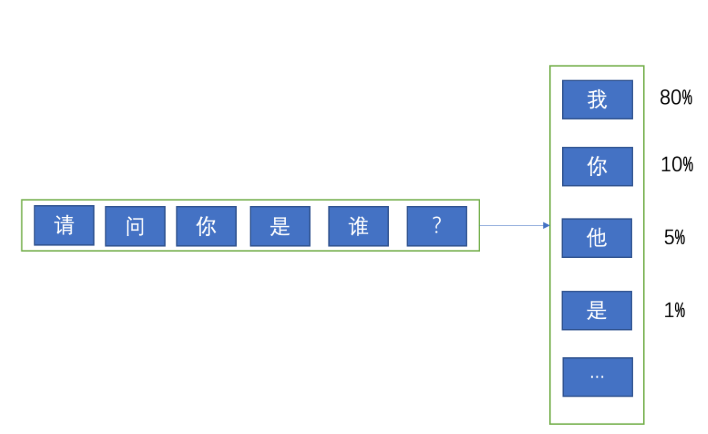
如上图:大模型推理的时候,会先通过用户的问题去计算第一个 token(首 token),而它计算的方法就是到词表中针对每个词去算一个概率,意思就是:根据用户输入的问题,去预测词表中每一个词会出现在回答的第一个 token 的概率,比如上图中 “我” 的概率是 80%,“你” 的概率是 10%,“他” 的概率是 5%,依此类推。 模型会计算出每个词出现在这个位置的概率。
但模型一定是取概率最高的那个词么? 很多时候不是的,不知道大家在使用大模型的时候有没有注意过 top k,top n,和温度这些参数。 因为现在的大模型几乎用的都是 sampling 模式,也就是说按一定的随机策略去采样,概率更高的词有更大的可能性会被采样到,但不是一定的。 所以模型启动的时候都要设置一个 seed 参数,就是一个采样的随机种子。 而 top k 参数,意思是按概率排序后,取前 K 个词进行采样。 比如 我设置 top k= 3, 那么在上图中 “我”,“你”,“他” 都有可能模型采样到并输出,只不过 80% 概率的 “我” 有更大的可能性被选中而已。sampling 模式下使用温度,top k,top p 来控制采样策略,所以大家会看到针对同一个问题,每次询问,模型给出的答案可能是不一样的。 这就是 sampling 模式的作用,之所以这样设计是为了让模型能更加的灵活,而不是每次都输出固定的答案。
注意:推理框架每次提测,都要测试精度,并且测试的时候需要保持 top k, top p, 温度这些参数是固定的,比如我们测试 deepseek-r1 的时候用的参数值就是论文中写的。 并选取一些开源的数据(比如 math500,都是数学题)来进行效果的评估。 因为都是数学题,都是要求输出的精准的数字,所以是可以自动化测试的。
为什么每次提测推理框架的性能优化,还要测试效果呢? 因为推理加速的很多策略,都是会影响精度的。 比如本来模型从 fp16 的存储精度变成了 int4,那么 int4 能存储的特征肯定比 fp16 的要少, 当然这带来的优点就是模型变小了, 计算变快了。 测试人员需要验证这样的优化是以不影响模型效果为前提的。
当模型计算出第一个 token 后,它会用用户的问题 + 第一个 token 再去预测第二个 token,如下图:
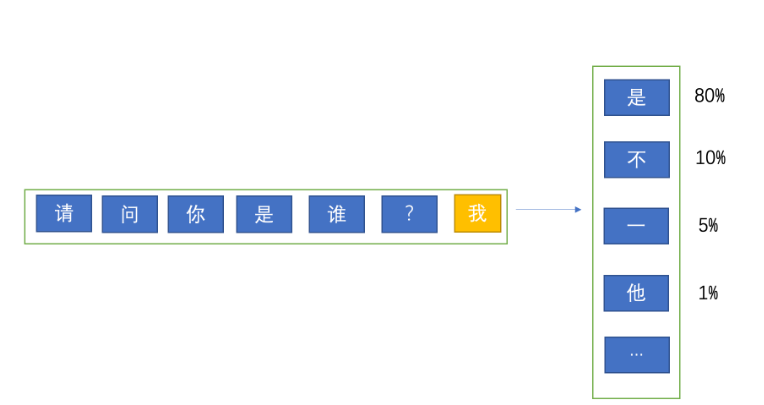
模型使用用户的问题预测出第一个 token,然后使用问题 + 第一个 token 去预测第二个 token,依此类推。
Prefill 与 Decode
上述的推理过程其实被划分成了两个大的阶段,分别是 prefill(预填充)和 decode(解码)阶段。prefill 阶段负责计算 K 矩阵和 V 矩阵并生成首 token,并且 K,V 会保存到 cache 中,而 decode 负责用 Q 矩阵去从 kv cache 中拿出 K 和 V,与 K 矩阵计算注意力机制,再与 V 矩阵计算特征,并输出一个又一个的 token 返回给用户。 其中的 Q,K,V 可以先不用纠结,如果大家想知道是怎么回事,那就大概可以理解成 Q 代表着用户的问题,K 是自注意力机制,Q 与 K 计算是计算出模型应该在上下文中的哪些 token 放更多的注意力(也可以叫权重),而 V 暂时理解成特征矩阵,当 Q 与 K 计算后,要与 V 计算生成最终的 token。
我们需要知道 prefill 和 decode 阶段各自在负责什么事情。尤其要明确以下几点:
- prefill 和 decode 阶段是可以各自优化的(后面会说 PD 分离)
- 通常首 token 是 prefill 阶段计算出来的,decode 阶段负责输出其余 token。所以首 token 耗时评估的是 prefill 阶段的性能,吐字率是评估 decode 阶段的性能,这个一定要记清楚。后面做单独优化的时候要知道什么时候关注首 token,什么时候关注吐字率。
- prefill 针对相同的用户问题,计算出来的 k,v 一定是一模一样的。 所以 kv 才会被缓存到 cache 中,decode 要从 cache 里拉 k,v 去计算。 所以有一种优化方向就是这种缓存的分布式化(毕竟有很多模型实例,如果能共享 k,v cache 就能提升性能)。或者缓存还是本地的,但是上层的路由要做哈希一致性计算,保证相同前缀的用户问题能路由到同样的 prefill 节点上,这样才能保证缓存命中。 同时需要注意的是缓存的命中做的是前缀匹配,就是不需要用户问一模一样的问题还会命中缓存,哪怕只有前几个 token 是一样的,那这几个 token 也会使用缓存中的 kv 而不是重新计算。
所以除了上面提到的精度测试外,第二个测试场景出来了,那就是针对 prefill 的优化,很常见的一个方式就是针对 kv cache 的优化,比如原来这些 cache 是存到 GPU 显存中的,我们可以把它优化到存到内存中以节省显存。 这里的测试方法大体上还是之前的那一套,但是需要注意的是:
- 在正常的性能测试中,为了避免命中 kv cache,我们通常都会在测试数据的最开始加上一个 uuid,只要前缀没有匹配到,那么就肯定无法命中缓存。而在优化 kv cache 的测试场景中,我们则要把 uuid 去掉,验证命中缓存后的性能收益。 PS:decode 阶段无法缓存,它必须每一次都重新计算生成 token,所以 kv cache 的优化在理论上对吐字率是没有明显影响的。
- 有些问题的输出很长,比如数学计算的思考过程超级长,经常思考个几分钟,10 几分钟甚至几十分钟的。 而我们现在的测试场景是在优化 prefill 阶段,关注的是首 token 的提升,而非评价 decode 阶段的吐字率,所以有时候为了压缩测试时间,可以设置模型的 max_tokens 参数,该参数限制模型输出的 token 长度。所以可以把它设置成一个很小的值来减少测试需要的时间。
- 测试方法可以使用同样的数据发送两次,验证第二次命中缓存后相比第一次节省了多少时间,但这只能作为基准测试,我们仍需评估上线后的缓存命中率和收益情况。因为:
- 线上模型是分桶的,且每个桶有 N 多个模型实例,如果 kv cache 是保存在本地,那么想命中就一定要把相同前缀(可以是前 N 个字符)的用户请求路由到同一个模型实例上,同时还要保证负载均衡,不能让某个模型实例负载过高。 所以这个调度策略其实是决定了缓存的命中率的。
- 线上每次命中多少 token 的前缀缓存是不确定的,也许命中了前 100 个 token,也可能命中 1W 个 token,所以不用真实的数据是评估不出来的。
- 缓存是有上限的,我们粗算下来 1K 的 kv cache 差不多占用 75M 的内存(这是在我们的环境中的表现),对于长文本(比如 100K),一条用户请求下来就占用了 7.5G,所以在线上流量比较大的情况下,内存空间很快就会被沾满,这样就需要把老的 kv cache 淘汰掉。 这导致原本可能会命中的数据因为之前的缓存被淘汰掉而无法命中。
所以基于以上情况,我们的测试场景需要设计成:
- 采集线上真实的数据,按时间排序,且只采集跟测试环境模型实例数量相同的线上模型实例的数据。比如测试环境只有 1 个模型实例, 那线上也采集 1 个模型实例的数据。否则模拟不出较为真实的缓存命中情况。
- 请求的 max_tokens 设置为 10,加速测试进程,只关注首 token 耗时
- 测试代码中把测试数据压入一个线程安全,先进先出的队列,保证每个压测的协程不会压重复的数据,且一定是按时间顺序取数据进行压测的。
下面是 locust 脚本中,数据的处理方式,主要是把数据压入队列,供每个压测协程使用









